

Procesador RISC implementado en una FPGA
2022 / Matías Bergerman, Agustín Galdeman, Franco Moriconi, Carola Pedrosa, Franco Scapolla
Este trabajo fue realizado para la materia 22.15 - Electrónica V, del Instituto Tecnológico de Buenos Aires.
Profesores: Ing. Andrés Carlos Rodríguez, Ing. Pablo Enrique Wundes.
Diseño original 🔗
Introducción 🔗
En este proyecto se implementa un procesador RISC sobre una FPGA usando Verilog. El hardware utilizado es la plataforma de desarrollo DE0-Nano de Terasic que cuenta con una FPGA Cyclone® IV EP4CE22F17C6N.
El procesador denominado EV22, por “Electrónica V 2022”, incorpora paralelismo a través de un bloque de Pipeline y se añade accesoriamente un periférico para la transmisión de video mediante el estándar VGA.
En principio, el esquema básico es el de la siguiente figura:
 Esquema del EV22.
Esquema del EV22.
El procesador EV22 es un procesador RISC cuyos buses y registros son de 16 bits. Sus opcodes (operation code), sin embargo, son de 14 bits, y posee un registro de constantes de 8 bits. La cartilla de instrucciones asociada contiene 27 instrucciones, y cada instrucción se corresponde con una única microinstrucción.
Las operaciones aritméticas se realizan a través de una ALU con dos entradas y una salida de 16 bits. Las entradas son A y B, y la salida se denomina Z en la ALU pero pasa a ser llamado Bus C a la salida del shifter. La entrada de A proviene de un multiplexor cuyas entradas son un registro del Register Bank o el valor presente en el registro de constantes. Los bits designados “aluc” determinan la operación aritmética a realizar por la ALU en cada microinstrucción. El registro B sólo puede tomar valores de registros dentro del Register Bank. La ALU dispone de un Carry Block para almacenar un bit de carry en caso de ser necesario en una operación, aunque también puede configurarse explícitamente a través de instrucciones.
La memoria donde se almacena el programa es de solo lectura, separada de la memoria donde se almacena información la cual es de lectura y escritura, por lo cual se trata de una arquitectura de tipo Harvard.
Posee un banco de registros con 35 registros. 28 de ellos son de uso general, 2 están asociados a pines de entrada, otros 2 a pines de salida, 2 son internos del Register Bank para uso auxiliar y permanecen inaccesibles de forma directa para el programador, y luego hay 1 registro denominado Working Register a través del cual el programador leerá valores de la memoria u otros registros y hará cálculos con ellos. Desde el punto de vista lógico es simplemente un registro más, pero la mayoría de las instrucciones trabajan con este registro de forma explícita y directa.
Flujo del programa 🔗
En la primer columna de la siguiente figura se muestran los opcodes de las instrucciones del EV22:
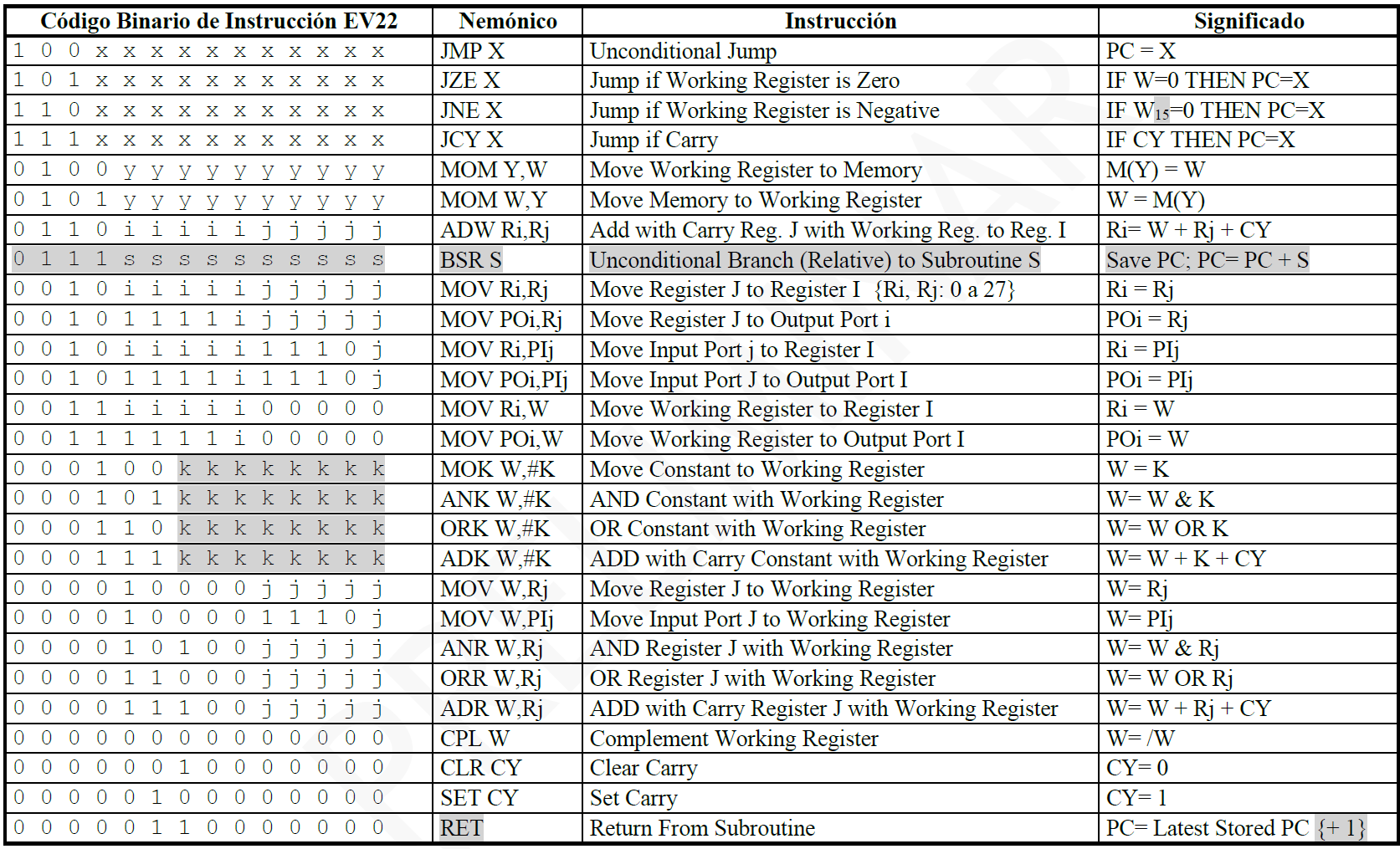 Cartilla de instrucciones del EV22.
Cartilla de instrucciones del EV22.
Es destacable que la mayoría tiene campos variables denotados por las letras “i”, “j”, “k”, “y”, “x” y “s”. En estos tramos de los opcodes simbolizados por letras, se introduce algún valor numérico que la propia instrucción utilizará en su operación. Por ejemplo, “JMP X” es un salto incondicional identificado por el valor “100” que define unívocamente al opcode y luego los siguientes 11 bits indican a qué posición saltará el Program Counter.
Habiendo establecido el formato de las instrucciones, el flujo de un programa en esta implementación de referencia es, en términos generales, el siguiente:
- Program Counter le indica a la memoria denominada “Program” qué posición de memoria devolver.
- Instruction Register interpreta la posición de memoria leída y propaga su contenido.
- Micro-instruction ROM interpreta la instrucción a microinstrucción y propaga al pipeline.
- Los campos ALUC, SG, KMx, etc. toman valores en función del opcode para setear el registro de constantes, los latches A y B, operación de la ALU, etc.
- La ALU realiza alguna operación, salvo en las instrucciones de salto.
- La salida de la ALU se almacena en algún registro del Register Bank o se usa para guardar información en la RAM denominada “DATA”.
La principal excepción a este flujo son los saltos, los cuales se determinan a través del “Bloque 1” que se vale directamente de los primeros bits del BUS de donde sale la instrucción junto a lógica combinacional y tiene entradas como Carry o el valor del Working Register, que se usan para determinar si un salto debe hacerse o no.
Implementación del EV22-G3 🔗
Cartilla de instrucciones 🔗
La implementación práctica, denominada EV22-G3, está basada fuertemente en el esquema propuesto en la sección anterior. Sin embargo, tiene algunas diferencias. Principalmente, la cartilla de instrucciones se vió modificada con dos bits adicionales por instrucción, generando opcodes de 16 bits en lugar de 14 para utilizar un largo de palabra más usual y a su vez agregar la funcionalidad necesaria para soportar constantes y registros de 16 bits. En la tabla siguiente se puede observar la cartilla del EV22-G3.
 Cartilla de instrucciones del EV22.
Cartilla de instrucciones del EV22.
Las principales diferencias son:
- Los opcodes poseen dos bits adicionales, llegando a 16 bits.
- Incorpora la instrucción NOP, que no existe en la cartilla original.
- Incorpora la instrucción LSK que permite definir el byte menos significativo de la constante.
- El opcode 0x0000 se utiliza para NOP en lugar de Complement Working Register.
- Los opcodes ANR, ADR, CLR y RET fueron modificados para que el B7 valga 0 y el B14 valga 1. Esto simplifica la lógica combinacional del decoder.
- Incorpora las instrucciones PIX RGB y PIX W para dar soporte al periférico de video VGA.
La instrucción LSK permite transformar el registro de constantes K en un registro de 16 bits, al cual se le carga la constante en dos pasos: Primero, se carga el byte menos significativo con LSK sin realizar ninguna otra operación. Luego, una segunda instrucción cargará el MSB y a la vez realizará alguna acción, como guardar el contenido del registro K en el Working Register o hacer alguna operación con el contenido del registro.
Los registros R26 y R27, además de poder ser utilizados como registros de propósito general, cumplen una función en el control del periférico VGA. Al ejecutar la instrucción PIX RGB cuyo color es una constante literal, o PIX W cuyo color corresponde a los últimos 3 bits del registro W, el periférico VGA modifica el color del pixel en la fila R26 y columna R27 de su memoria RAM interna para escribir el color indicado.
Agregar dos bits adicionales a cada opcode aprovecha mejor los buses y registros del procesador los cuales son de 16 bits. Estos bits adicionales se utilizan para distinguir los diferentes opcodes más fácilmente a la hora de decodificarlos.
Implementación lógica en Intel® Quartus® Prime Software 🔗
La traducción de bloques del esquema original a la implementación en Quartus no es directa. No obstante, a fines prácticos, las funciones y la intención original de estos bloques se mantiene.
Fetch Unit 🔗
Para analizar la implementación, se parte del comienzo del flujo de programa. Se implementó una Fetch Unit alimentado por clock con un contador que cumple el rol de Program Counter, su única salida. Esta fetch unit contiene lógica que modificará el program counter si alguna instrucción lo demanda, como los saltos o llamados/retornos de subrutinas.
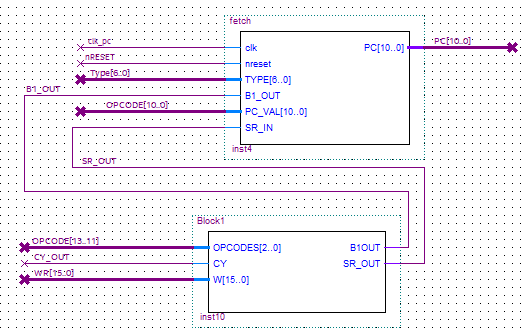 Fetch Unit y Block 1.
Fetch Unit y Block 1.
Las entradas que tiene el Fetch Unit son:
- clk_pc: Clock que alimenta al bloque y avanza el contador.
- nReset: Botón de reset. Tiene asociado un input físico.
- Type: Toma la salida “type” de la microinstrucción actual como condición para tomar decisiones
- B1_OUT: Toma la salida de un bit del Block 1 que le indica si debe realizar algún salto.
- Opcode: Usa algunos bits del opcode actual para tomar decisiones.
- SR_OUT: Se usa para tomar decisiones respecto a llamados y regresos de subrutinas.
Por otro lado está el Block 1, quien funciona de forma muy similar al esquema original presentado. Sus entradas son:
- OPCODE: Usa bits del opcode para tomar decisiones.
- CY_OUT: Se usa para decidir si saltar en la instrucción JCY X
- WR: Se usa para decidir si saltar según valga cero o sea negativo para las instrucciones JZE X y JNE X respectivamente.
Sus salidas son:
- B1_OUT: Le indica al Fetch Unit si debe modificar el PC porque se cumplen las condiciones de un salto.
- SR_OUT: Le indica al Fetch Unit si debe modificar el PC porque se vuelve de una subrutina.
Entre estos dos bloques, se controla el flujo del programa. El program counter alimenta una ROM con el programa a ejecutar cargado.
ROM 🔗
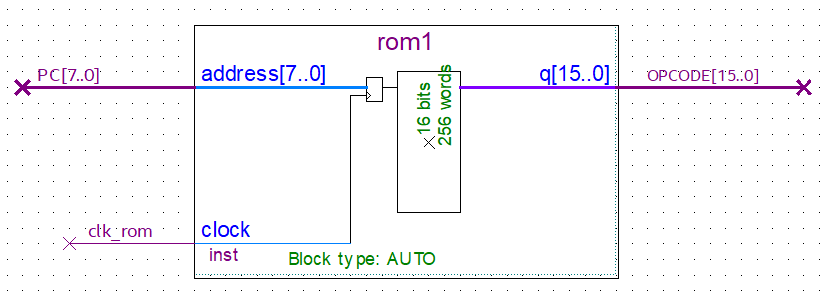 ROM donde se almacena el programa.
ROM donde se almacena el programa.
La ROM es simplemente una memoria alimentada por el PC quien señala cual posición debe leerse y envíar su contenido a la salida. Un clock alimenta un latch que permite que a la ROM le llegue dicho PC. Su salida no tiene latch alguno, como se genera por defecto en Quartus, ya que se necesita que el nuevo OPCODE salga de forma inmediata para la siguiente etapa del ciclo de una instrucción.
Decoder 🔗
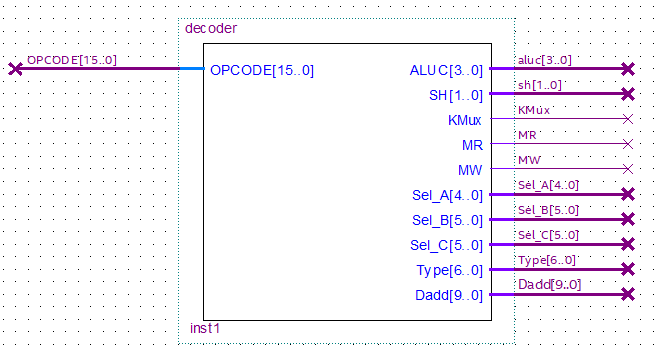 Decoder.
Decoder.
El Decoder es un bloque que engloba los módulos que interpretan las instrucciones y luego las microinstrucciones. Su único input es el opcode que sale de la ROM alimentada por el PC y un clock. Con el valor del opcode, usa un switch case que, en función del opcode, devuelve los valores de ALUC, SH, KMux, MR, MW, etc; que la cartilla indican. Así, traduce el opcode y le con estas salidas influencia al resto del procesador para que cumpla con la tarea especificada en el opcode, señalando el tipo de operación de la ALU, cuales registros utilizar, cual dirección verá de la RAM, si es una operación de lectura o escritura, etc.
Constant Register 🔗
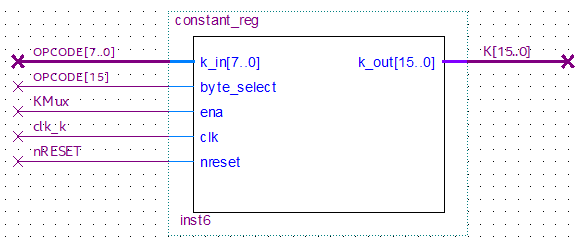 Constant Register.
Constant Register.
Este registro recibe, a partir de ciertos opcodes, valores de 8 bits que almacenará en su parte alta o su parte baja según corresponda y así formar una palabra de 16 bits que luego alimentará a la entrada A de la ALU. No obstante, su salida pasa primero por un MUX que luego elegirá si A debe recibir el valor de este registro o de algún registro del Register Bank.
Entre sus entradas, dispone de:
- OPCODE[7..0]: Si la instrucción implica cargar valores a este registro, dicho valor se encuentra en estos bits del opcode.
- OPCODE[15]: Si la instrucción actual modifica al registro de cualquier forma, el bit más significativo es quien indica si los 8 bits se cargan en el LSB (si vale 0) o en el MSB (si vale 1).
- KMUX: Viene del Decoder. Si vale 1, este registro utilizará las entradas anteriores para cargar un nuevo valor donde corresponda. Si vale 0, no hace nada.
- clk: Es el clock quien alimenta al registro y está sincronizado de forma tal que sólo actúa luego de que se actualiza el PC y ya salió el nuevo opcode.
- nRESET: Si se activa el reset, este registro se limpia y pasa a valer 0 por defecto en sus 16 bits.
ALU 🔗
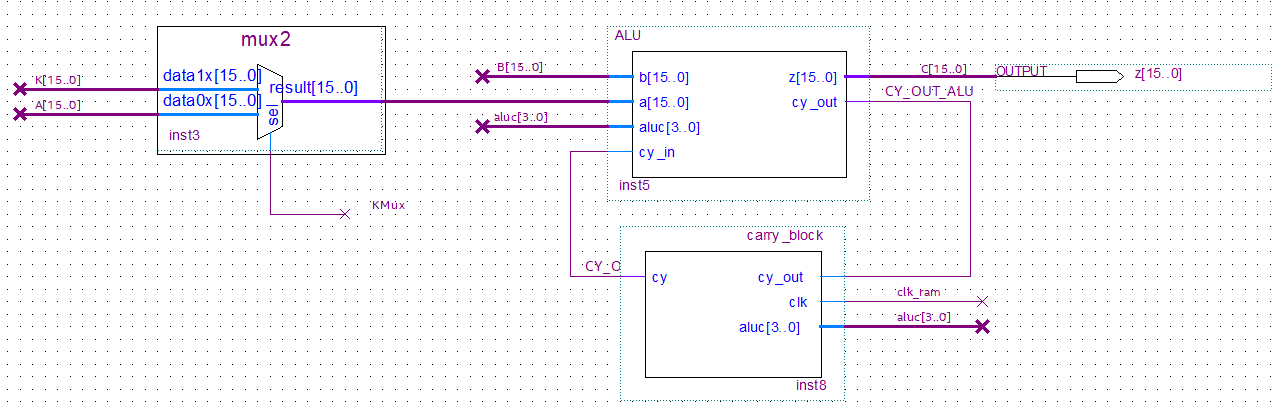 Unidad aritmética lógica (ALU).
Unidad aritmética lógica (ALU).
La ALU funciona de la misma forma que el esquema original. Entradas A y B, una entrada CY proveniente el carry block el cual a su vez la ALU alimenta y una salida Z. No es incorporó shifter ya que ninguna operación de la cartilla lo utiliza, pero podría incorporarse sin mayores inconvenientes. La ALU no es alimentado por ningún clock, todas sus operaciones ocurren ni bien cambia algún parámetro a su entrada. Como se mencionó antes, A proviene de un MUX que elije cual dato leer, B viene exclusivamente del Register Bank y Z, o C, va de forma directa al Register Bank.
El Carry Block actualiza el carry sólo cuando ALUC le indica que la ALU realizó una operación que modifica el carry, entre las cuales se incluye set carry y clear carry.
Register Bank 🔗
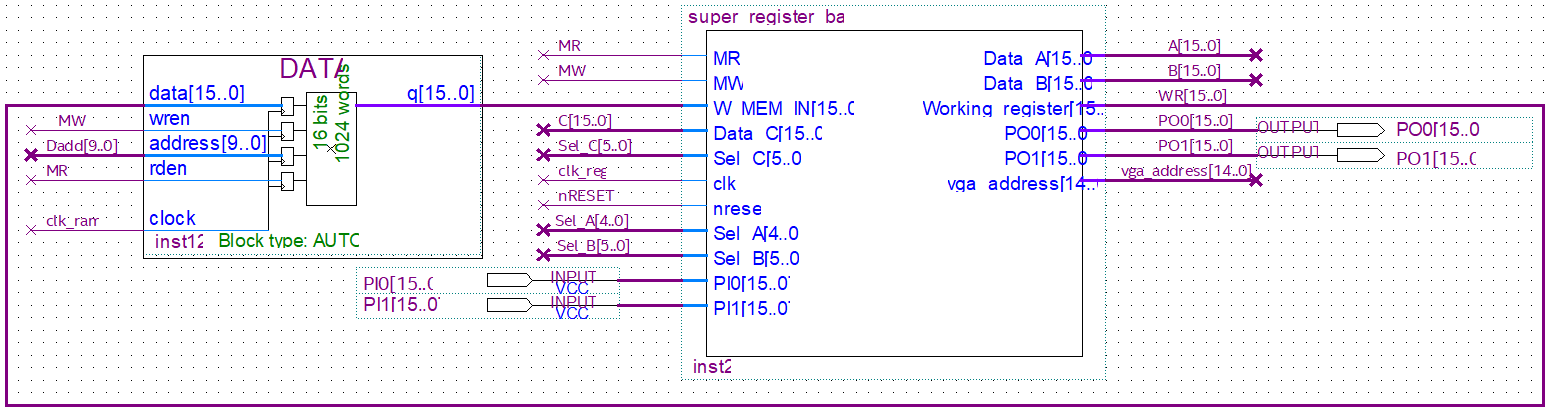 Register Bank y Data.
Register Bank y Data.
En la figura se muestra el bloque Register Bank y la RAM donde se guardan datos si un opcode lo indica. Register Bank se separa en múltiples sub-etapas. Se muestra el diagrama original propuesto por la cátedra para explicar la implementación a partir de él.
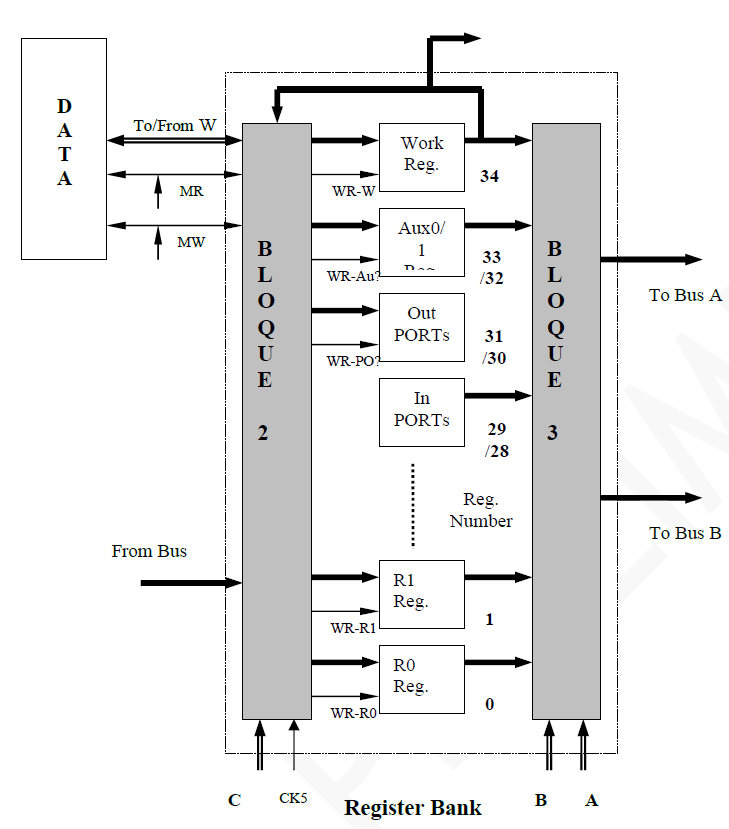 Esquema original de Register Bank.
Esquema original de Register Bank.
Internamente, el Register Bank se separa en tres partes:
- Bloque 2: Se comunica con la RAM de forma bidireccional utilizando MR y MW. También recibe la salida de la ALU, un clock y un valor (llamado C en la figura) que indica en qué registro guardar el contenido del bus C. Su salida es dicho valor de Bus C en la dirección indicada por la entrada correspondiente.
- Bloque 3: Se comunica con los buses A y B para realizar operaciones con la ALU. Sus entradas son los valores de los registros, y qué registros leer para A y para B. No tiene clock alguno.
- Registros: Todos los registros explicados en la primera sección. La salida del Working Register se usa para la lógica del bloque 1 y va hacia el bloque 2 para guardar el contenido en memoria, o cargarla, según corresponda.
En la implementación práctica, el Bloque 2 y la zona de registros no se distinguen de ninguna forma. Directamente, se incorporó ambas secciones en un único bloque dentro de un “always” de Verilog. Separarlos de forma explícita se traducía en una capa adicional de complejidad que no generaba aporte alguno, y traía problemas de sincronismo en Verilog.
El bloque 3 en esencia no es más que dos multiplexores cuya entrada son todos los registros (excepto los pines de output), con lo cual se mantuvo separado del bloque 2 y el espacio de registros. Se implementó como una función de verilog, de forma tal que cuando un opcode cambia los valores de los registros a leer en A y B, instantáneamente actualiza a la ALU con el nuevo valor.
Las entradas del Register Banks son:
- MR: Indica lectura de la RAM
- MW: Indica escritura en la RAM
- W MEM IN: Entra el valor leído de la RAM
- Data_C: La salida de la ALU, por el BUS C
- Sel_C: Viene del Decoder. Indica donde guardar el contenido del Bus C.
- clk: El clock que alimenta a la lógica correspondiente a las funciones del bloque 2
- nRESET: Reset. Si se activa, todos los registros vuelven a cero
- Sel_A: Viene del Decoder. Indica qué registro debe leer la entrada A de la ALU
- Sel_B: Viene del Decoder. Indica qué registro debe leer la entrada A de la ALU
- PI0: Puerto de input 0
- PI1: Puerto de input 1
La RAM recibe MR y MW que le indican si se está realizando una operación de escritura o de lectura. Dadd, proveniente del decoder, le indica qué dirección de memoria leer, de la misma forma que PC lo hacía con la ROM. Tiene una entrada “Data” para operaciones de escritura que proviene de la salida del working register, ya que este registro hace de mediador entre los registros comunes y la RAM, y tiene una salida “q” la cual se usa en operaciones de lectura.
Pipeline 🔗
Etapas del Pipeline 🔗
El esquema seguido para la división en distintas etapas del pipeline fue muy similar al propuesto por la cátedra, con las diferencias en el bloque de decoder mencionadas anteriormente. El bloque decoder es una combinación de las etapas de decode y operand, mientras que luego le siguen las etapas de execute y retire. Además otro cambio que se planteó es el de implementar al bloque UC1 como un bloque puramente combinacional.
Bloque UC1 🔗
El bloque UC1 es el encargado de insertar NOPs en la parte baja del pipeline en los casos que se den las condiciones de hold. Con ese objetivo, es necesario solamente poner el valor de C en 35, para que el resultado no sea guardado e insertar ceros en el campo type. Además debe ser posible propagar las señales de lectura o escritura de memoria al resto del pipeline.
 Bloque UC1.
Bloque UC1.
Resolución de Conflictos: bloque UC2 🔗
Otro bloque fundamental para el funcionamiento del procesador es el bloque UC2, el cuál se encarga de resolver las dependencias entre instrucciones, y en caso de encontrar conflictos entre ellas, disparar la señal de Hold para esperar que se vacíe el pipeline y así evitar errores en los programas. Para evaluar si existen conflictos entre instrucciones se reciben las señales Type2, Type3, Type4 y Type5, SelA2, SelB2, SelC3, SelC4 y SelC5. Las señales Type dan una referencia de qué registros son escritos y leídos por cada instrucción. El orden y denominación para cada bit utilizados fue el siguiente:
\[T_i = [b_j^i \quad b_{CW}^i \quad b_{CR}^i \quad b_{RW}^i \quad b_{RR}^i \quad b_{WW}^i \quad b_{WR}^i ]\]\(T_i\) se corresponde con la señal Type i-ésima, b es cada bit con sus subíndices representando la interacción con cada registro (J para el PC, R para registros de uso general y W para el working register).
Utilizando éste esquema es posible identificar 4 tipos de conflictos:
- Que el working register se quiera leer cuando la etapa 3, 4 o 5 quieran escribirse
- Que el carry se quiera usar cuando la etapa 3, 4 o 5 quieran escribirlo.
- Conflictos en los casos de haber saltos.
- Conflictos en los registros de uso general, debe evitarse que las etapas bajas del pipeline quieran escribir en ellos y las etapas altas quieran leerlos al mismo tiempo.
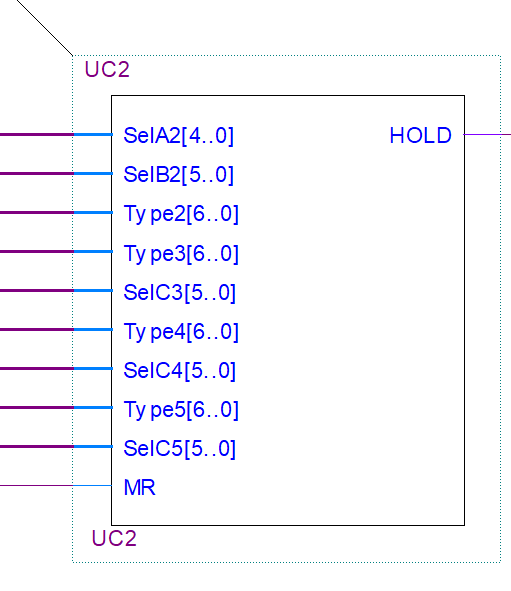 Bloque UC2.
Bloque UC2.
Registros del pipeline 🔗
El resto del pipeline se compone de dos registros MIR2 y MIR3. Estos registros propagan las señales correspondientes a las siguientes etapas y a los módulos del procesador que lo requieran. Cada uno recibe su clock con el desfase necesario para permitir la correcta propagación.
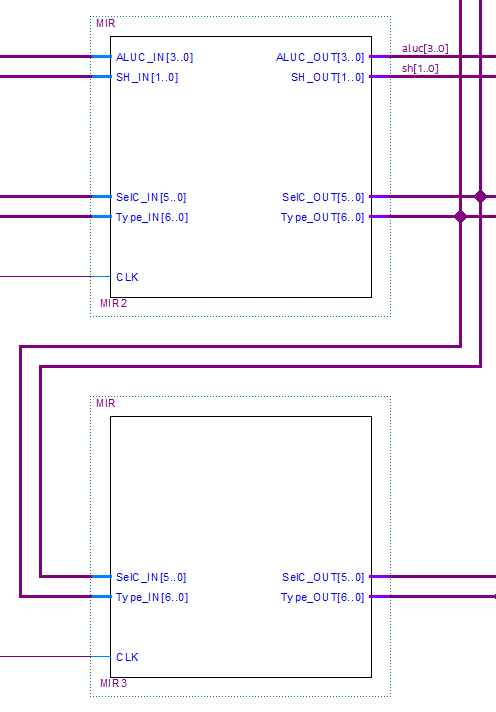 Pipeline.
Pipeline.
Mejora incorporada: Periférico VGA 🔗
Por fuera del esquema básico del EV22, se incorporó una memoria RAM adicional. Esta RAM utiliza dos clocks. Uno a la entrada, para operar la RAM de VGA de la misma forma que la ROM de programa y la RAM de Data, y un segundo clock a la salida cuya frecuencia está dictada por la pantalla a utilizar, ya que la salida de esta memoria sale físicamente por pines de la FPGA utilizada hacia un puerto VGA que se conecta a un monitor.
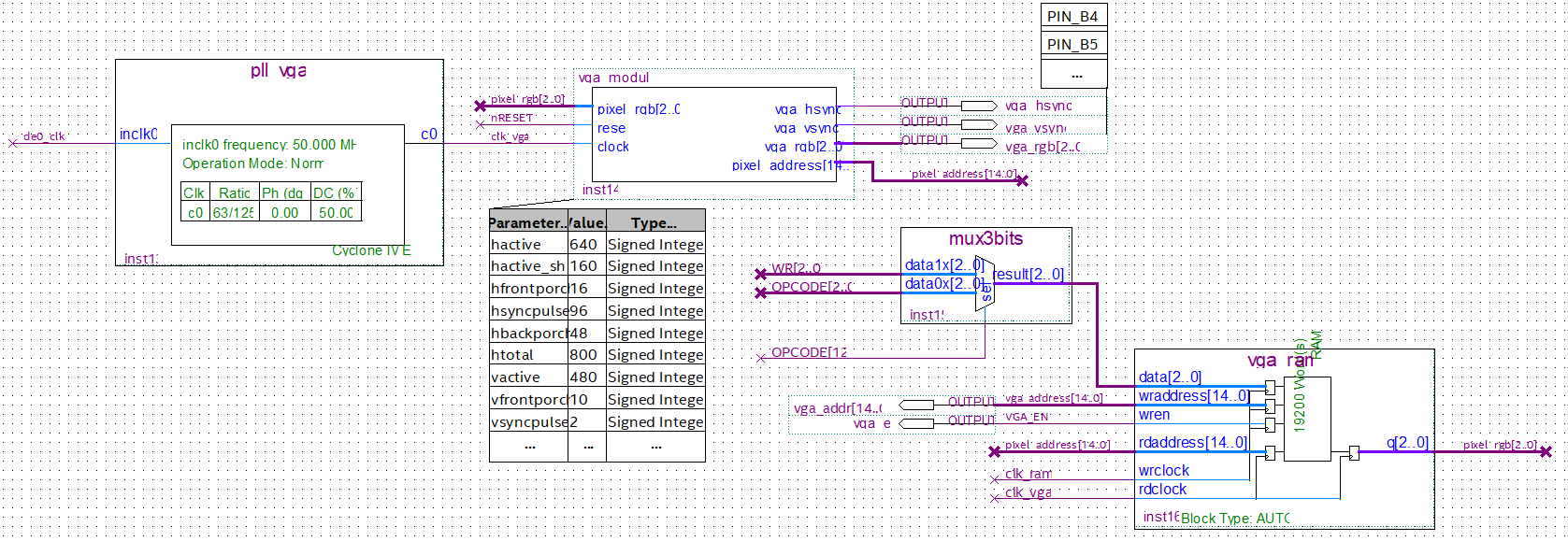 Lógica VGA.
Lógica VGA.
Se dispone solo de ocho colores, ya que cada pixel se ve representado por tres bits. La resolución no es especialmente grande, como consecuencia de la memoria disponible en la FPGA. No obstante, imagenes arbitrarias que se usaron de ejemplo lograron verse con relativa claridad a pesar de las limitaciones de hardware. Se realizaron pruebas de manipulación de la imagen en tiempo real, lo cual funciona sin mayores inconvenientes a excepción de necesitar calcular manualmente bloques de código con contadores y jumps a partir de la frecuencia de los clocks para manejar los tiempos de cambio de la imagen.
La memoria de la RAM se puede inicializar mediante un Memory Initialization File (MIF), el cual se genera a partir de una imagen JPEG usando un programa de Python1.
Simulaciones 🔗
Para realizar códigos en Assembly para las simulaciones, como también para evaluar en la FPGA, se implementó un compilador simple en Python que realiza la traducción automática de las abreviaciones de cada opcode en la secuencia de bits correspondiente, para ser cargada a la FPGA usando el formato HEX (Intel hexadecimal object file format).
Simulación funcional sin pipeline 🔗
En la figura siguiente se muestra una simulación ejecutada en Quartus con un código sencillo que genera una sucesión de Fibonacci:
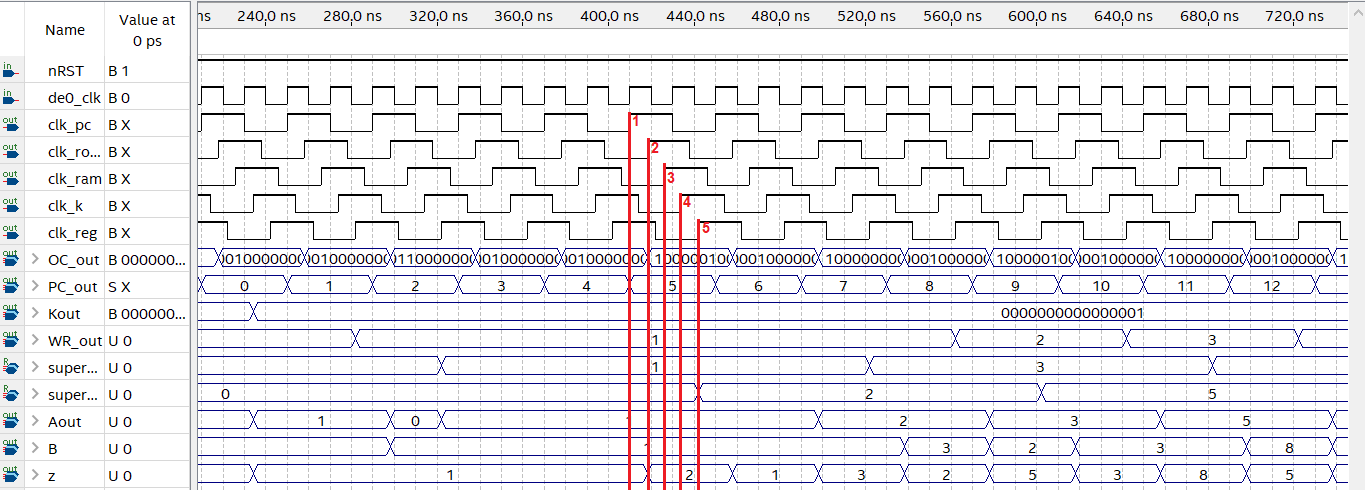 Tiempos en un programa estándar.
Tiempos en un programa estándar.
Código Assembly que genera la sucesión de Fibonacci:
LSK #K 1 // K_lsb = 1
MOK W,#K 0 // K_msb = 0; Wr = K
MOV Ri,W 0 // Mover Wr a R0
LSK #K 1 // K_lsb = 1
MOK W,#K 0 // K_msb = 0; Wr = K
// Repeat the next 4 instructions in eternum:
ADW Ri,Rj 1 0 // R1 = Wr+R0
MOV W,Rj 0 // Wr = R0
ADW Ri,Rj 0 1 // R0 = Wr+R1
MOV W,Rj 1 // Wr = R1
...
En la figura se observan cinco lineas rojas, que vinculan a los clocks desfasados con los cambios de valores en las diferentes etapas del flujo de programa. El orden propuesto y utilizado para el correcto funcionamiento del procesador fue el siguiente:
- Program Counter
- Latch entrada ROM
- Latch entrada RAM
- Registro Constantes (K)
- Register Bank
Esta enumeración se corresponde con la mostrada en la figura de la simulación. Primero, aumenta el Program Counter, lo cual se traduce en un cambio de opcode. En este caso, no se accede a informacion en la RAM con lo cual el clock denominado “clk_ram” no genera cambio alguno. Luego cuando comienza un ciclo del clock del registro de constantes, este se actualiza al valor que se le cargó a través del opcode correspondiente, aunque en este caso particular el Fibonacci sólo requiere que se haga una vez al principio del programa para inicializar la sucesión, con lo cual este cambio no está alineado con la línea 4. Finalmente, se actualiza el Register Bank almacenando o leyendo algún registro según se le pida. En la figura se muestra cómo el resultado del cálculo en la ALU (z) se almacena en uno de los registros.
El PLL utilizado funciona a 50MHz, pero el procesador trabaja a 25MHz. Este valor se eligió por las limitaciones del analizador digital utilizado para medir la implementación del procesador en una FPGA real. El analizador utilizado fue el de la Digilent Electronics Explorer, cuyas limitaciones de ancho de banda a la hora de tomar muestras comienzan a ser notorias a frecuencias mayores a 25MHz. La simulación de timings de Quartus sugiere que no debería existir inconvenientes en utilizar frecuencias mayores, como el doble o cuádruple de los 50MHz que ingresan al PLL, pero al ser imposible verificarlo en la práctica se decidió que lo más seguro era utilizar una frecuencia donde se pueda confirmar el correcto funcionamiento de la FPGA con el procesador cargado.
Pruebas 🔗
El EV22-G3 fue programado sobre la FPGA Cyclone IV presente en la placa de evaluación DE0-Nano. Se conectó a la placa un monitor VGA usando algunos componentes pasivos para adaptar los niveles de tensión.
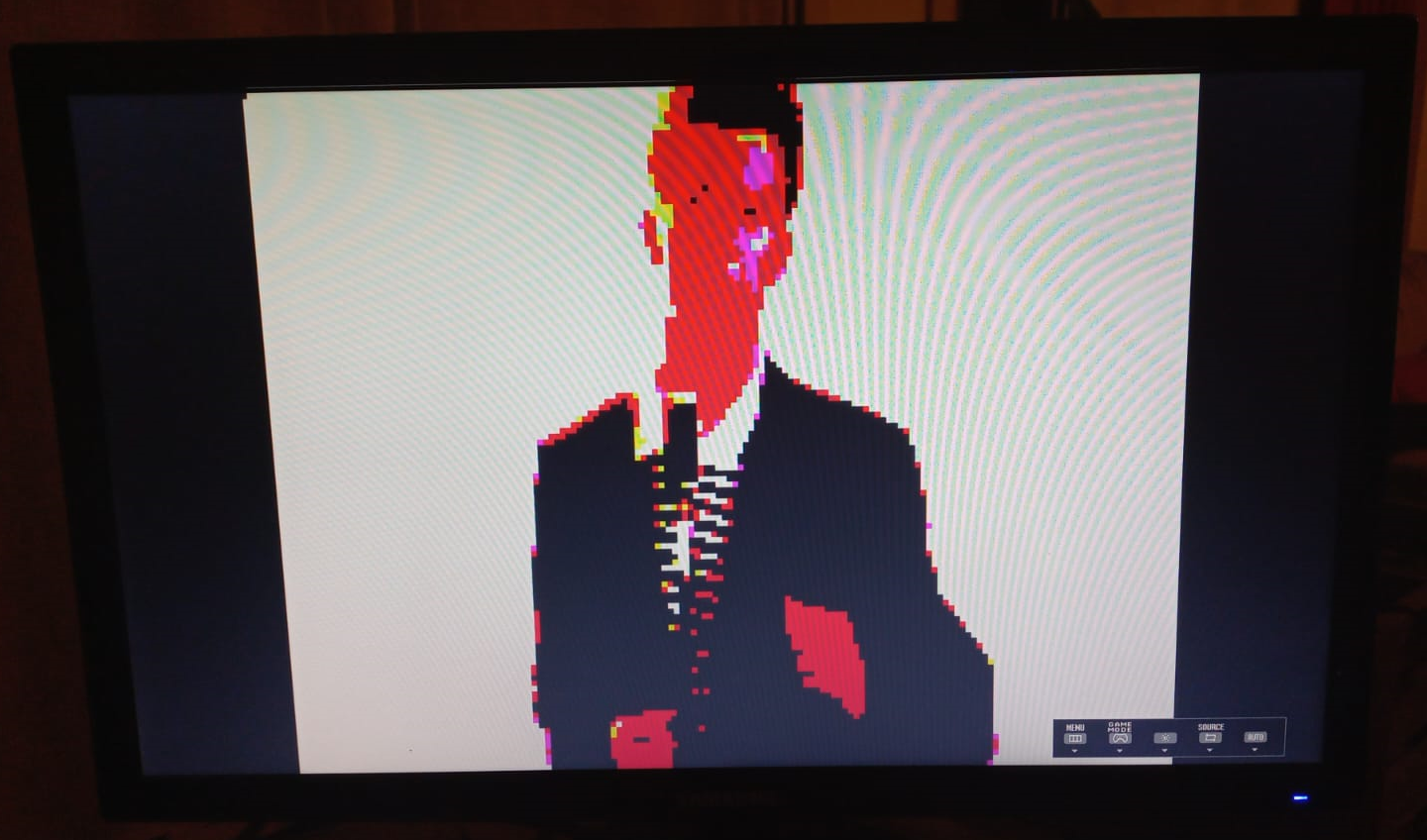
En las figuras a continuación se pueden ver dos ejemplos de imagenes que fueron precargadas en la memoria del periférico VGA, junto con una fotografía del monitor cuando se conecta con la FPGA. La resolución de la imagen producida es de 120x160 para utilizar menor memoria, pero esta puede ser fácilmente ampliada mediante la adición de más memoria a la FPGA. Sin embargo, para lograr una cantidad de colores mayor a 8 debería agregarse un DAC que pueda producir los valores analógicos correspondientes a cada color.
Fotografía de Don Featherstone original, y la recreación en un monitor por el EV22-G3.


Fotografía de Rick Astley original, y la recreación en un monitor por el EV22-G3.

Por último, a modo de ejemplo, se puede ver un código en Assembly que recorre pixel por pixel la memoria RAM del periférico de VGA y pinta de color azul toda la pantalla, a excepción de un rectángulo de 16x16 que se pinta de color rojo. Modificando el valor de 4 registros de propósito general es posible dibujar el rectángulo en cualquier posición de la pantalla, y el periférico de VGA actualizará la imagen.
LSK #K B0 // Cargo el indice X // K_lsb = B0
MOK W,#K FF // K_msb = FF; Wr = -80
MOV Ri,W 03 // Mover Wr a R3
LSK #K C4 // Cargo el indice Y // K_lsb = C4
MOK W,#K FF // K_msb = FF; Wr = -60
MOV Ri,W 04 // Mover Wr a R4
LSK #K 00 // Cargo el contador de colores // K_lsb = 00
MOK W,#K 00 // K_msb = 00; Wr = 00
MOV Ri,W 02 // Mover Wr a R2
LSK #K 00 // Cargo el contador de colores // K_lsb = 00
MOK W,#K 00 // K_msb = 00; Wr = 00
MOV Ri,W 02 // Mover Wr a R2
LSK #K 88 // Cargo el contador de filas // K_lsb = 88
MOK W,#K FF // K_msb = FF; Wr = -120
MOV Ri,W 0 // Mover Wr a R0
LSK #K 00 // Cargo el valor de fila // K_lsb = 00
MOK W,#K 00 // K_msb = 00; Wr = K
MOV Ri,W 1A // Mover Wr a R26
LSK #K 60 // Cargo el contador de cols // K_lsb = 60
MOK W,#K FF // K_msb = FF; Wr = -160
MOV Ri,W 1 // Mover Wr a R1
LSK #K 00 // Cargo el valor de columna // K_lsb = 00
MOK W,#K 00 // K_msb = 00; Wr = K
MOV Ri,W 1B // Mover Wr a R27
MOV W,Rj 03 // Traigo el indice X // Wr = R3
ADR W,Rj 1B // W = W + R27
JNE X 29 // Comparo R27 con el indice X // No pintar (jmp 41)
LSK #K F0 // Cargo el -ancho X // K_lsb = F0
MOK W,#K FF // K_msb = FF; Wr = -16px
ADR W,Rj 03 // W = W + R3
ADR W,Rj 1B // W = W + R27
JNE X 21 // Comparo R27 con X+width // Pintar (Check Y)
JMP X 29 // Pinto color de fondo // No pintar (jmp 41)
MOV W,Rj 04 // Traigo el indice Y // Wr = R4
ADR W,Rj 1A // W = W + R26
JNE X 29 // Comparo R26 con el indice Y // No pintar (jmp 41)
LSK #K F0 // Cargo el -alto Y // K_lsb = F0
MOK W,#K FF // K_msb = FF; Wr = -16px
ADR W,Rj 04 // W = W + R4
ADR W,Rj 1A // W = W + R26
JNE X 2B // Comparo R26 con Y+height // Pintar (jmp 43)
PIX RGB 01 // Pinto de color Azul (fondo)
JMP X 2C // Continuo, avanzo PC en 2
PIX RGB 04 // Pinto de color Rojo (rectangulo)
LSK #K 1 // K_lsb = 1
MOK W,#K 0 // K_msb = 0; Wr = K
ADW Ri,Rj 1B 1B // R27 = Wr+R27
ADW Ri,Rj 01 01 // R1 = Wr+R1
MOV W,Rj 01 // Wr = R1
JZE X 33 // Me salteo el JMP X
JMP X 18 // Vuelvo a ejecutar PIX RGB
LSK #K 1 // K_lsb = 1
MOK W,#K 0 // K_msb = 0; Wr = K
ADW Ri,Rj 1A 1A // R26 = Wr+R26
ADW Ri,Rj 00 00 // R0 = Wr+R0
MOV W,Rj 00 // Wr = R0
JZE X C // Termina la imagen
JMP X 12 // Reinicio las columnas